



まえがき
ローカルでChatGPT的なの使いたいと思ったことはありませんか?私はあります。
かなり前に導入しようと調べたことはあるのですが、Win & ラデ環境は例によってアレで結局投げました。 が、現在はLM Studioを使えば導入・利用難易度がかなり下がっています。
私も実際に導入してみたので、今回はLM Studioをとりあえず使えるようにするまでの記事になります。
導入方法
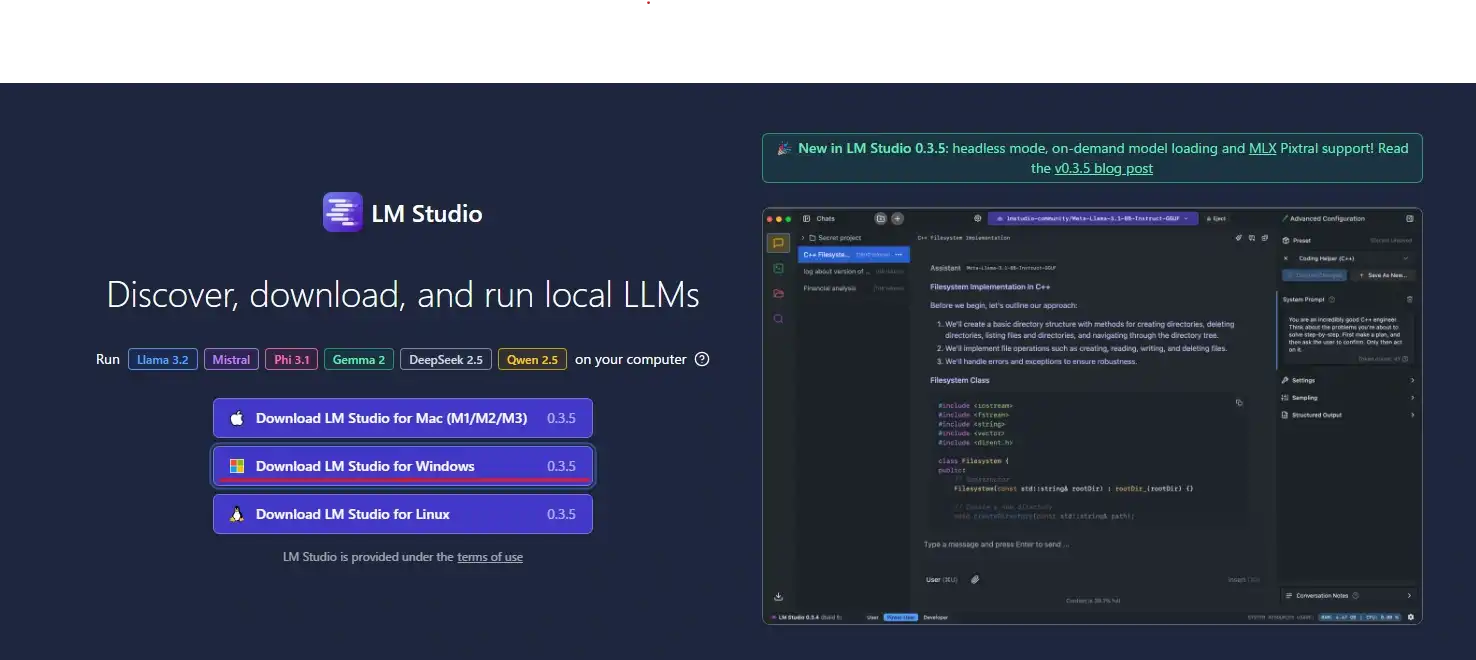
以下が配布元URLです。執筆時点でのバージョンは0.3.5でした。
まあ見たまんまなのですが、画像赤線部からWindows版をDLします。
保存したインストーラーを実行すれば、自動でCドライブ内にLM Studioがインストールされたのち、ソフトが立ち上がります。
…はい。Cの固定フォルダ以外にインストールできません。 インストーラー形式のWin対応LLMは大体こうです。 モデルデータの保存場所だけは後から別フォルダを指定可能なので、無駄にCを圧迫する事態は避けられます。
それ以外をCから出したい場合は、シンボリックリンクでも作りましょう。 LM Studio関係のフォルダはおそらく以下の3か所なので、動かす方はどうぞ。
%USERPROFILE%\.cache\lm-studioモデルデータやチャットログ等の保存先%APPDATA%\LM-Studioおそらくキャッシュファイル関係%LOCALAPPDATA%\LM-StudioLM-Studio本体インストール先
初期設定
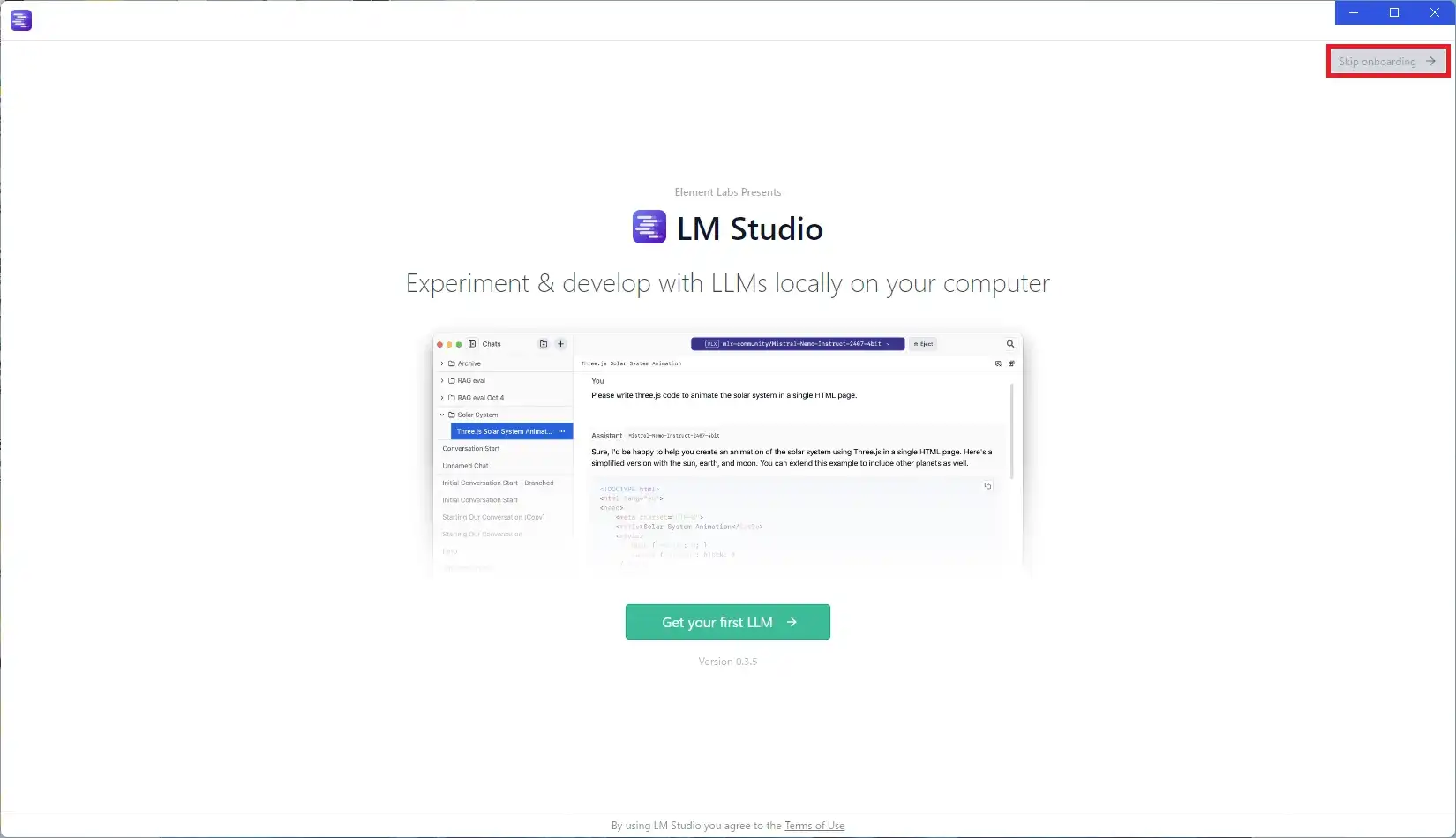
インストール直後は下記画面のようになっていますが、赤枠を押してスキップしてください。 このチュートリアルで導入されるデータは日本語だとまともに扱えません。
デフォルトだとCドライブにモデルのデータが入ってしまいます。 別ドライブに動かしたい方は、以下画像赤枠のフォルダマークからモデルデータ一覧を開き、保存先の変更を行ってください。
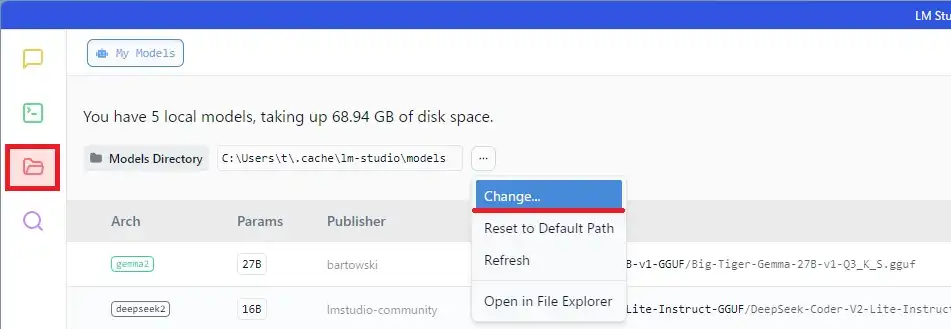
画像は後から撮ったためモデル導入後となっていますが、導入前でも可能なはずです。
Windows HIP SDK向け設定
このままモデルデータ導入と行きたいところですが、
Windows HIP SDKが扱える環境の場合は、先に以下の操作を行ってください。
長文生成時のパフォーマンスが上がります。
まず赤枠内虫眼鏡か歯車マークのどちらかをクリックします。
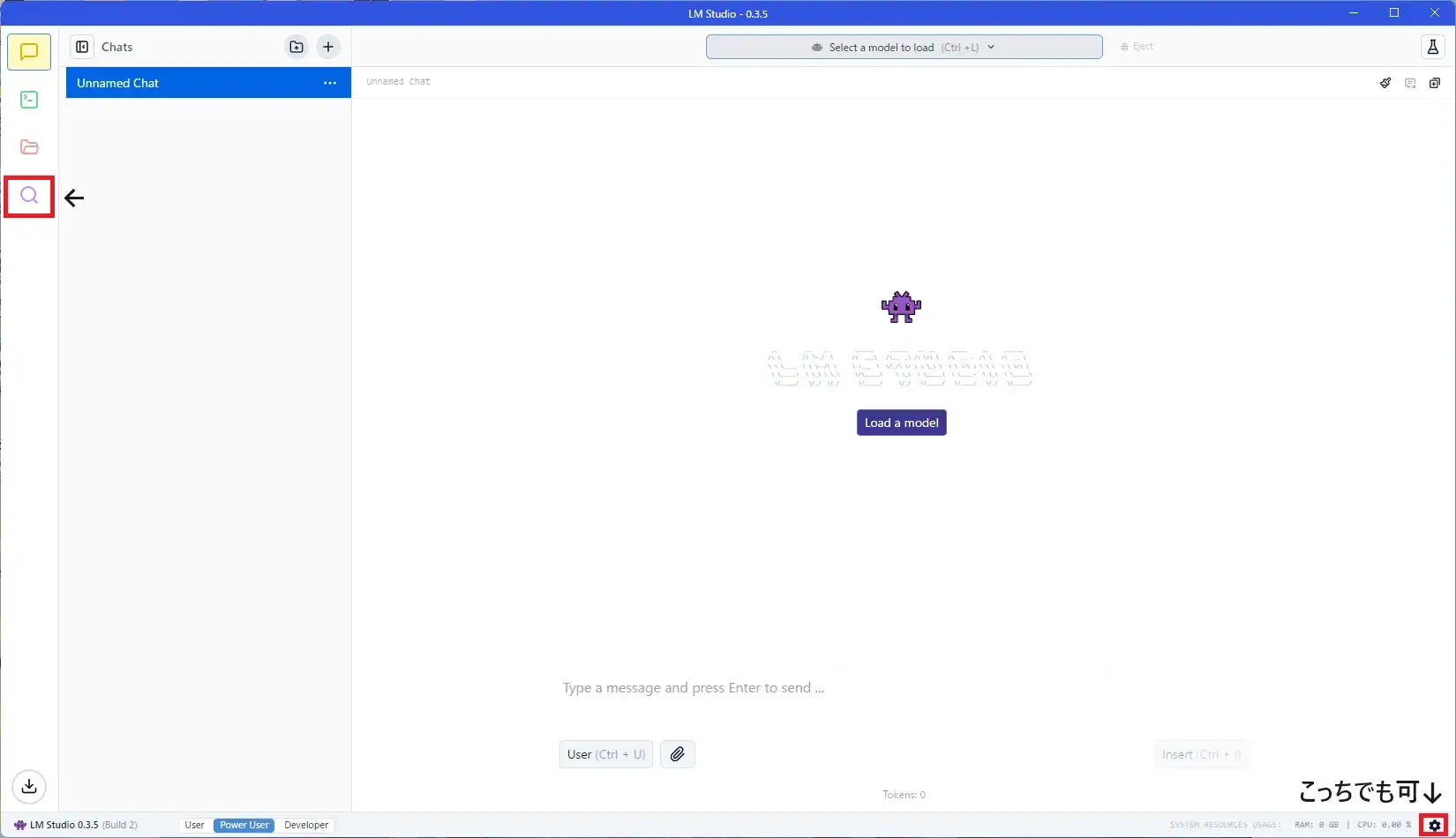
Mission Controlというのが表示されます。
左側にあるRuntimesをクリックすると、対応環境ならROCm llama.cpp (Windows)というのが表示されているはずです。
とりあえずクリックしてインストールしてください。
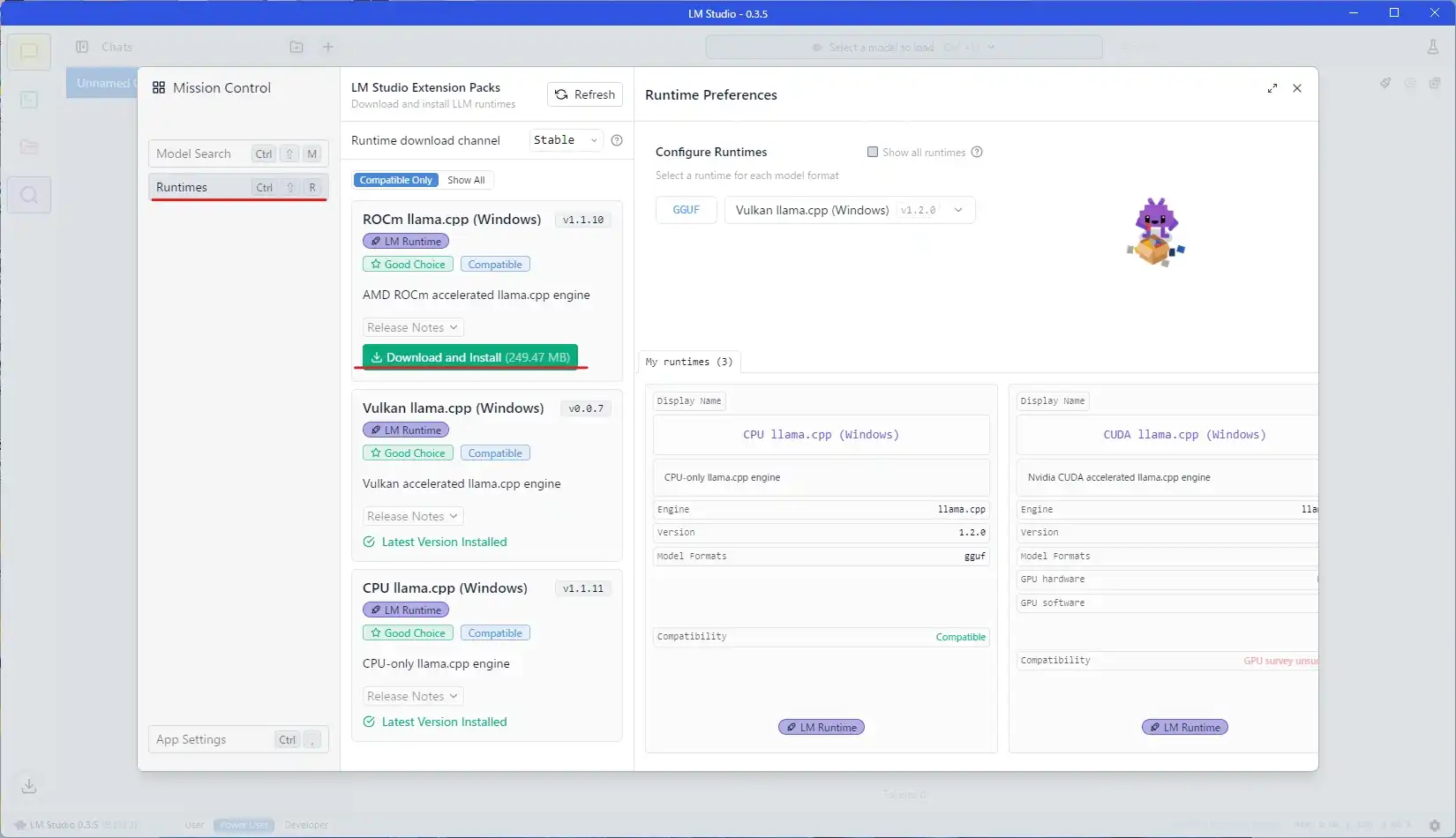
デフォルトでGGUFのデータはVulkanでのGPU処理を利用する設定になっています。
プルダウンを開き、今導入したROCm llama.cpp (Windows)に変更してください。
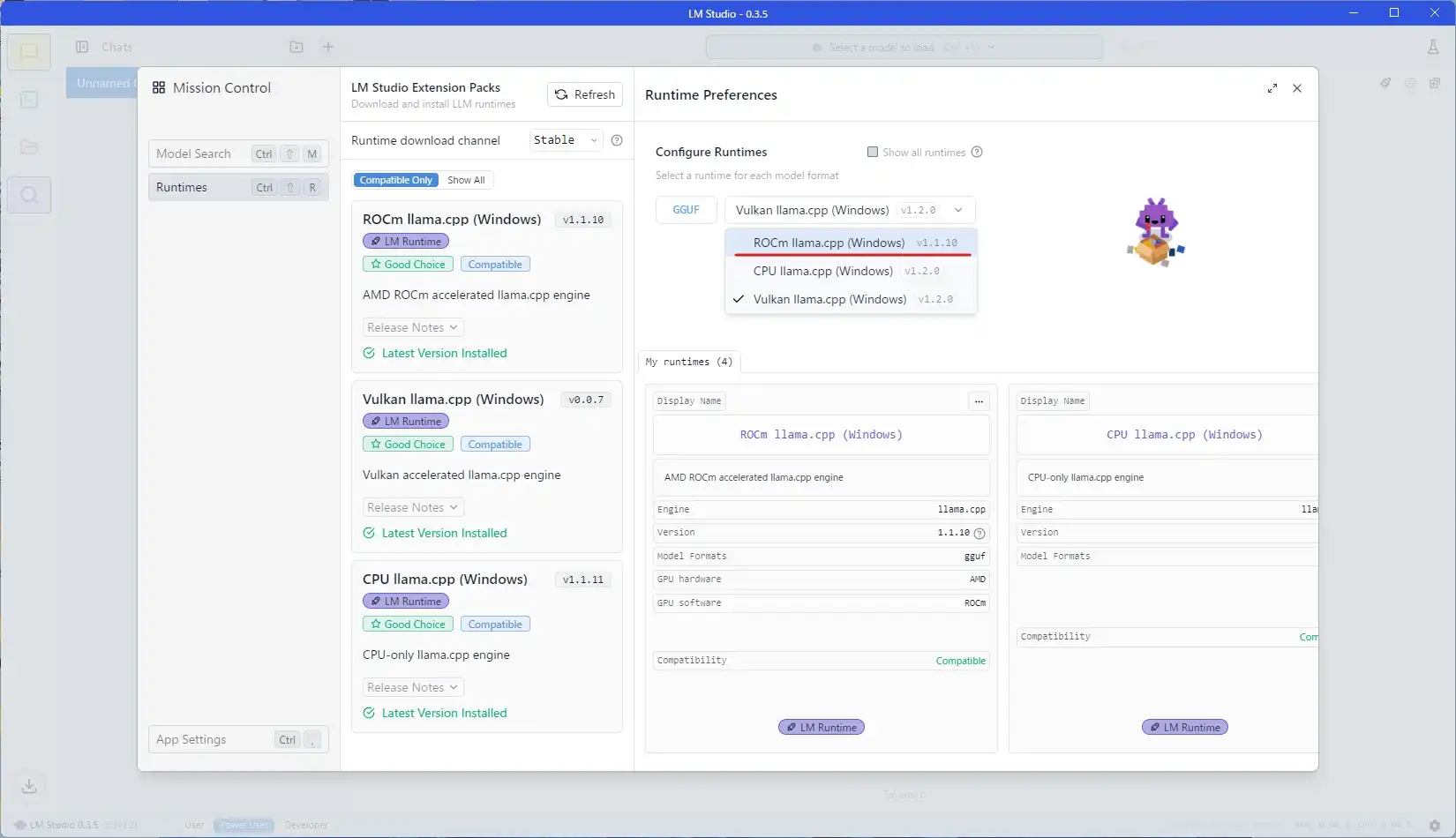
Geforce環境の場合は初めからCUDA向けのcppが入っているようです。
モデルデータ導入
次にモデルデータをダウンロードします。 LM Studioを通して保存することができるのですが、LLM初心者の場合は非常に参考になるUIとなっています。
この点だけでLM Studio一択であると言っても過言ではありません。
同じ画面のModel Searchをクリックしてください。 HIP SDK向けの説明を飛ばした方の場合は、GUI左側に表示されている虫眼鏡マークから同じ画面が開けます。
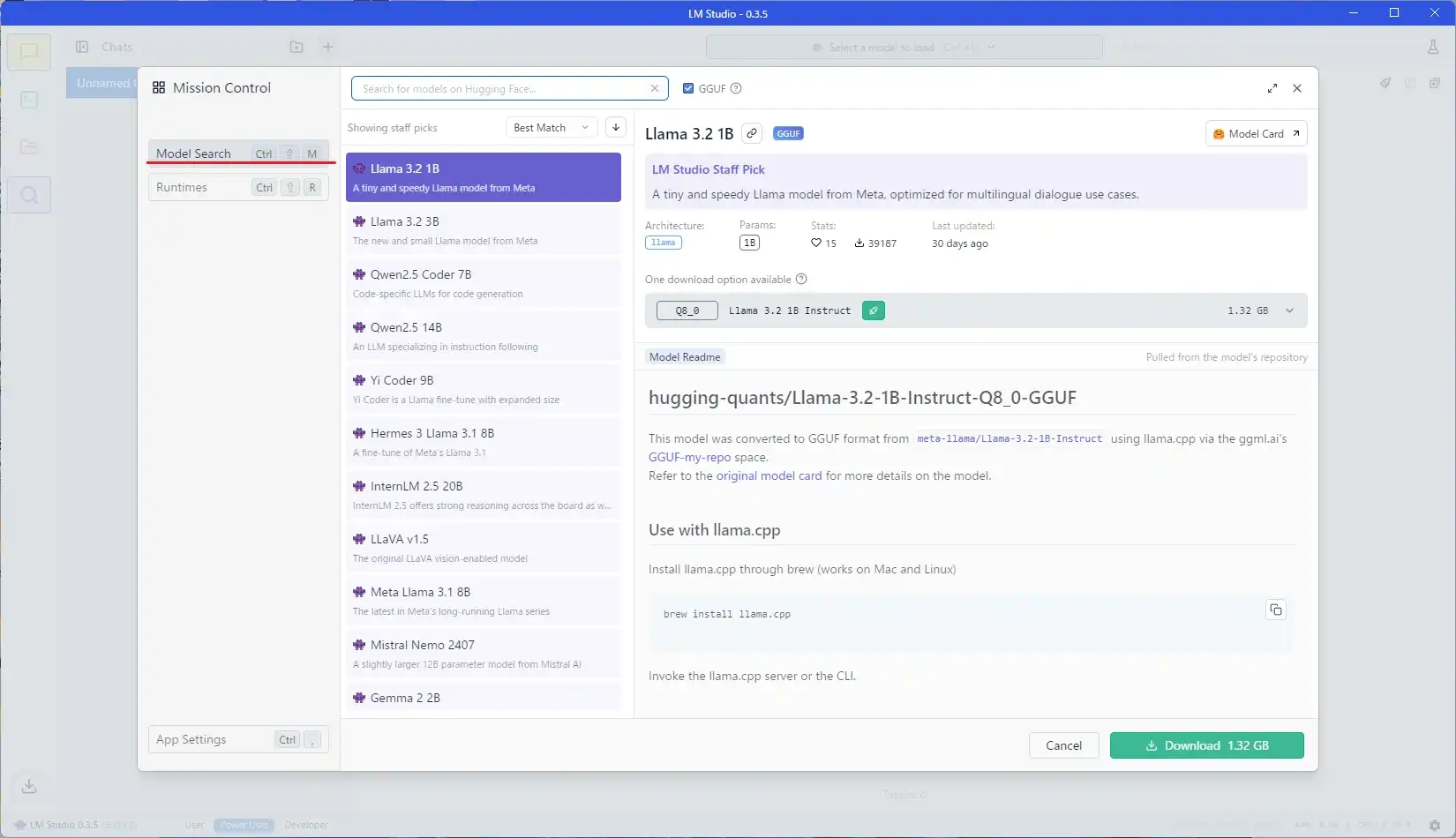
上部検索窓に導入したいデータの名前を入れると、内容を絞り込めます。 とりあえず日本語対応らしいSwallowを検索し、13Bモデルをクリック。
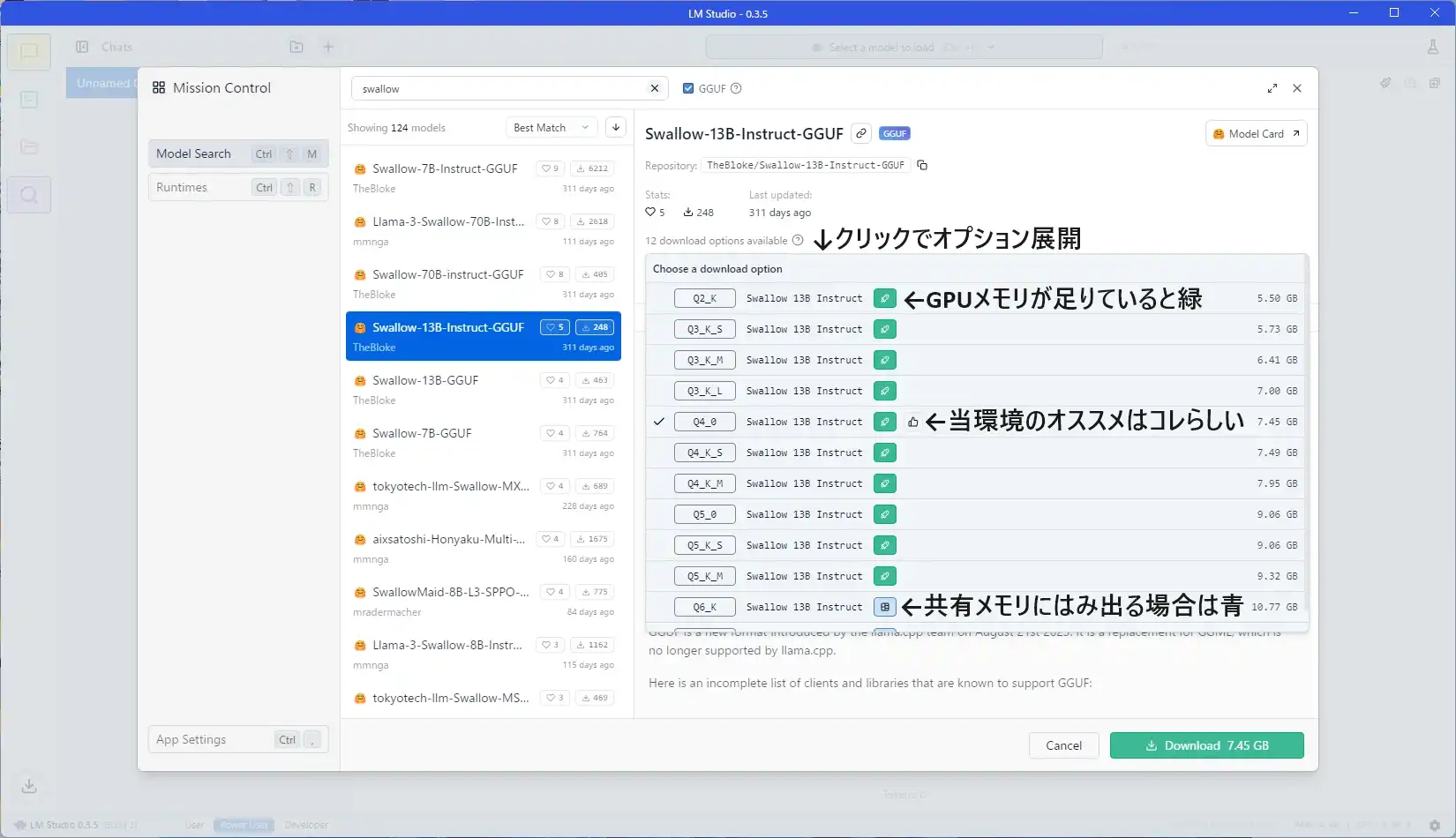
基本的にモデルを選んだ段階で、その環境でのおすすめのデータ形式が選択されるようです。
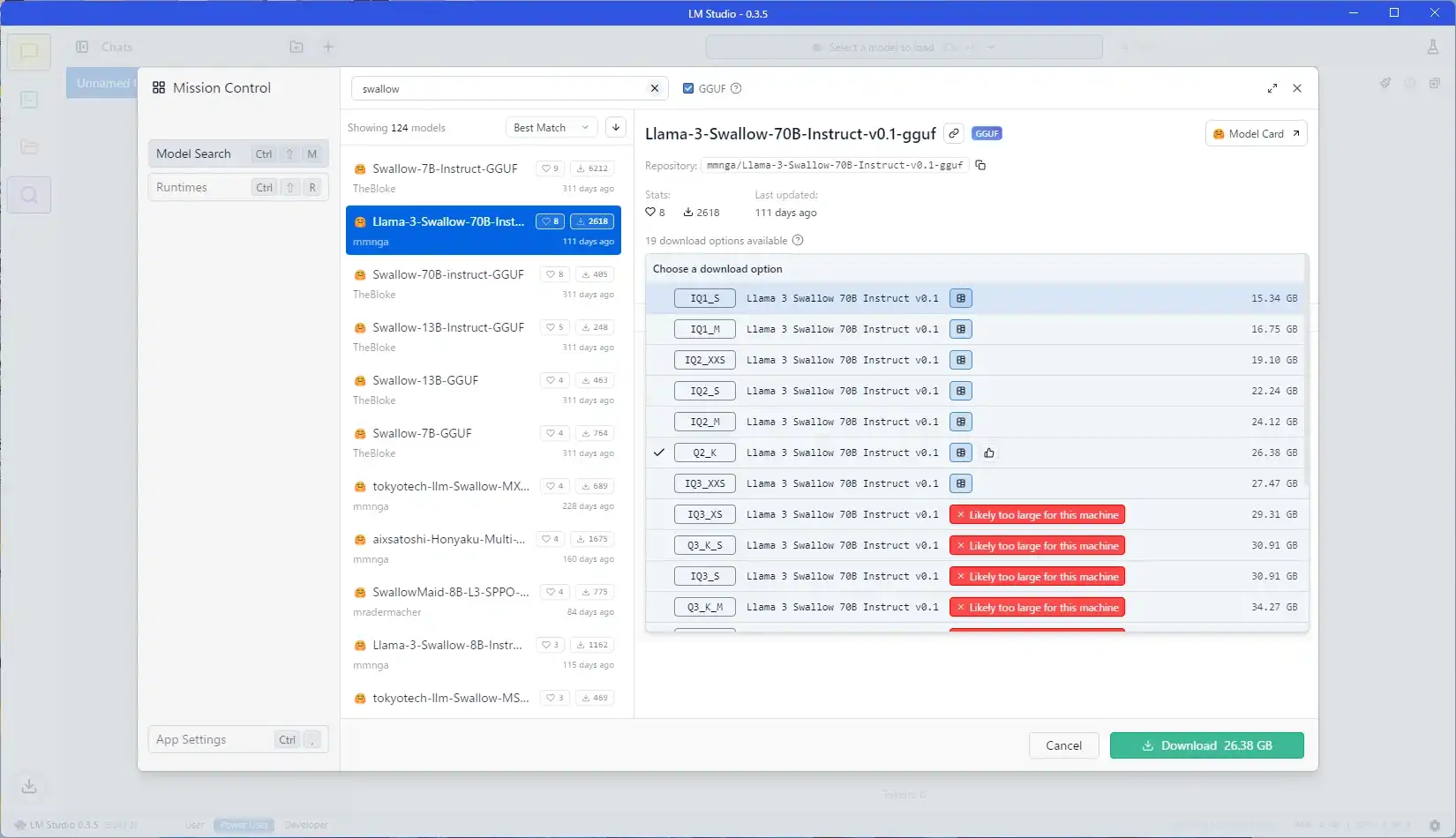
画像に書いていますが、緑マークがついているものは専用GPUメモリのみでの処理が可能です。 青マークは専用メモリだけでは足りず共有GPUメモリ、つまりPCメモリも処理に使う必要が出る場合に表示されます。 また、共有GPUメモリを使っても足りないサイズのデータでは、以下画像のように赤色表示となります。
初心者の場合、緑マークでbit数が低すぎず、かつパラメーター数の大きいモデルを選ぶのが手堅いです。
bit数の大きさがそのまま質に繋がるので、ここが低いと大規模モデルでも回答の精度が低下します。 青マークでGPUのみでの読み込みが不可能なモデルは、当環境だと遅すぎて使い物になりません。 私の使っているPCメモリはDDR4-2666なので、これがDDR5の高速モデルの場合は話が少し変わるかもしれません。
IQ○○となっているものはIMatrix量子化モデルというものらしいのですが、I無しと比較して処理に時間がかかります。 HIP SDK利用の場合は多少遅いで済みますが、Vulkanの場合は緑表示でも青レベルに低速でした。 そのためVulkanは選べるモデルが少し少ないです。
メモリが16GBなRX6800の場合は、このブラウザ上でのファイルサイズの記載が10.4GB未満までのものが、緑マークとなるようです。 ただし、青マークとなっているGemma2 27BのK3_S(12.17GB)でも、GPUメモリのみで読み込めはしました。 デフォルト設定でメモリ使用量14GB超えなのであまり余裕はないですが、簡単なやり取りくらいはできるのを確認しました。
一つ注意点としてLM StudioのDL機能ではGGUF版のみを落とすため、本家モデルだとライセンス同意が必要なモデルも簡単に落とせてしまいます。 意図せず本家のライセンスに違反してしまわないようお気を付けください。
今回の説明ではLlama 3 Swallow 70B Instruct v0.1のQ2_Kをダウンロードしています。
App SettingsからUIの言語を日本語にもできますが、その辺はお好みでどうぞ。
User Interface Complexity Levelは動作に関わるので、Power userのままのほうがいいです。
利用方法
ひとまず動作させるための最低環境は整いました。実際に使ってみます。
GUI上部のSelect a model to loadをクリックするか、ショートカットCtrl+Lを押すと導入済みのモデル一覧が表示されるので、利用するモデルを選択します。
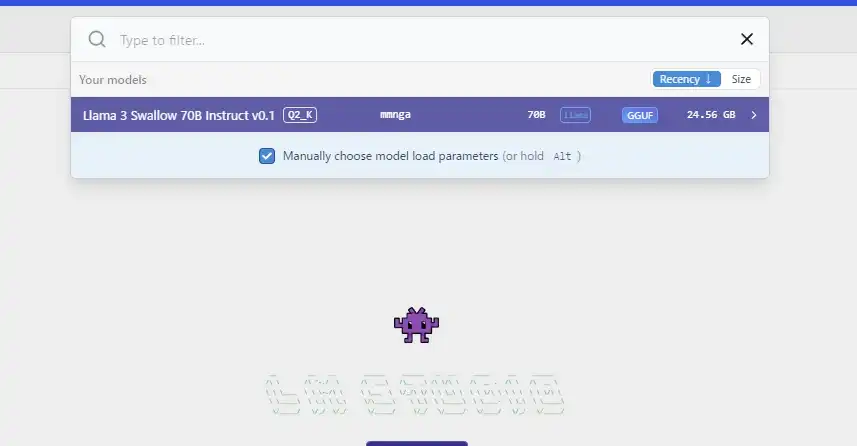
するとモデルを読み込む前に、以下のような設定画面が出てきます。
そのまま使えば普通なら問題は起きません。 LLMに関して知識がないならむやみに触らないほうがいいでしょう。
一応Context lengthは重要そうなので触れておくと、モデルが扱える文章の長さに関係します。
長文入力でトークン数の肥大化が予想される場合、先にこの数値を増やしておくといいかもしれません。
ただしここを大きくしすぎると、メモリ使用量に大きな影響を与える可能性があるという警告が表示されます。
コード向けモデルだと5桁まで指定できたりしますが、やりすぎは禁物。
またモデルによっては生成パフォーマンスが悪化する模様。
GPU OffloadはGPUのメモリ量に合わせて自動変動します。
前述の緑マークのデータなら勝手にMAXに設定されフルロードとなりますが、今回は青マークのデータなのでこうなります。
ここを減らせば緑データでもPCメモリへの割り当てが可能です。
Context lengthめっちゃ増やしたい時とかは必要かもしれません。
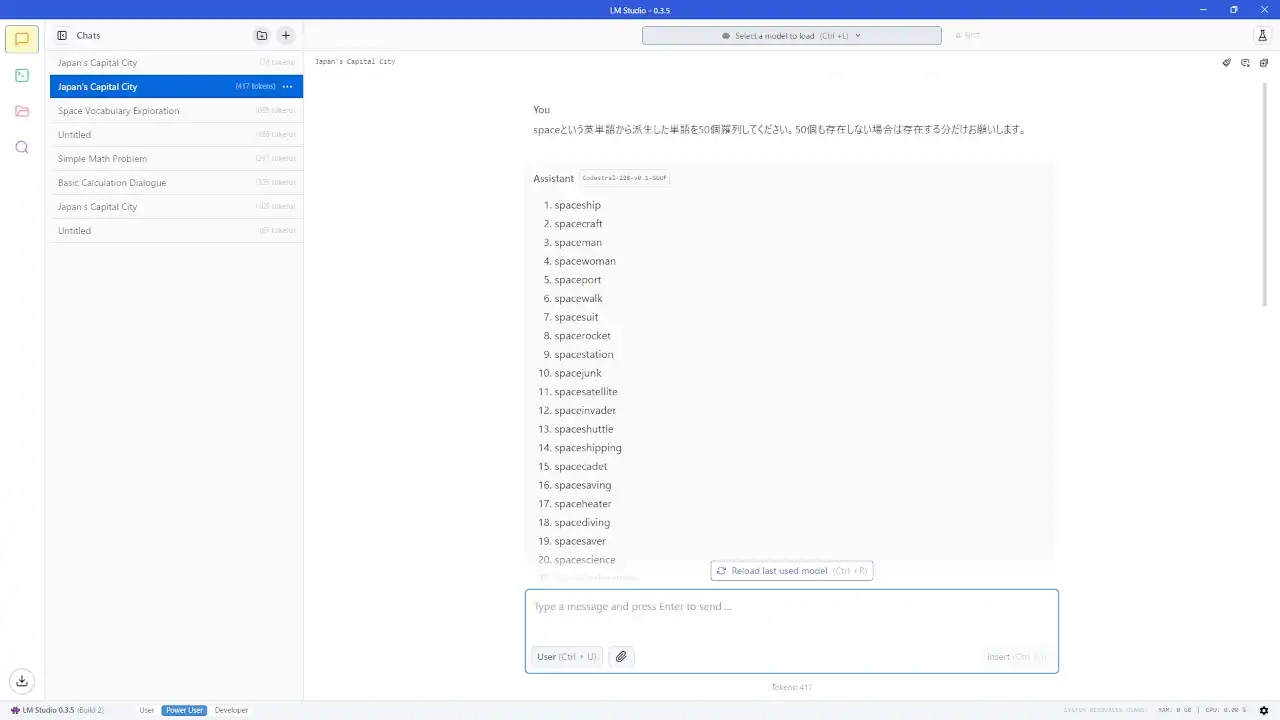
Load ModelクリックかCtrl+Enterで読み込んだら、ついに利用可能になります。 試しに日本の首都を聞いてみました。
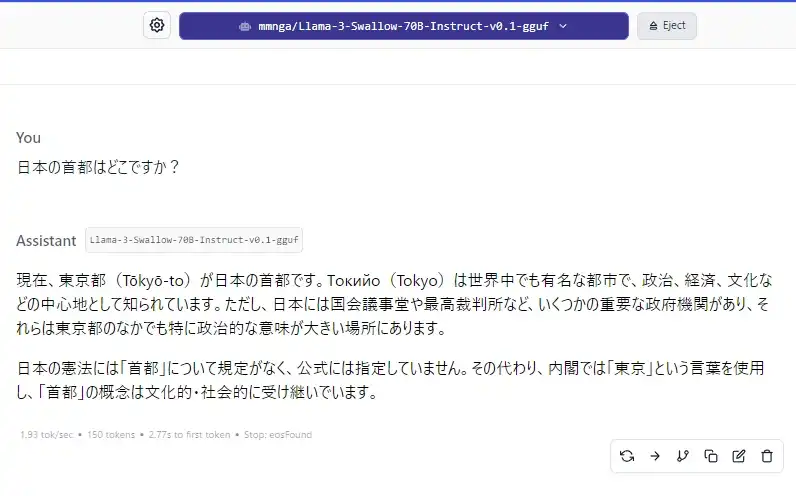
2bitモデルを利用したためか文章が少し変ですが、内容は大体あっています。 日本の首都は実際には指定がないというところまで出力されました。 まあここまで細かく出たのはこの一回だけで、その他は単に東京が首都という回答しか出ませんでしたが…
パラメーター数の少ない幾つかの日本語向けモデルで何度か試しましたが、「日本の首都は一般的には東京とされているが、正式には定まっていない」という旨の回答は得られませんでした。 1度しか出なかったとはいえ、流石はパラメーター700億の日本語対応モデルです。
ただ、
大容量を常用はキツいっす…
出力下部に記載されていますが、1トークンの生成が平均2.7秒なので、これだけの文章でも大分時間がかかりました。 ここまで遅いと流石に各種無料サービス使ったほうがいいです。 DDR5-8000とかだとマシになるんですかね…?
GPUのみで読み込みが済むモデルの場合は、もちろん高速に生成できます。
他のモデルに切り替える場合
今使っているモデルから別のものに切り替える際は、以下画像赤枠のEjectを押して、先にメモリを解放したほうがいいかもしれません。
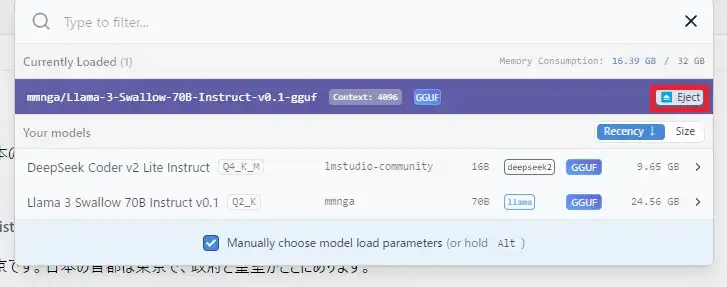
モデルを読み込んだままの状態で切り替えを試みると、GPUオフロードの数値がおかしくなることがあります。 手動で戻せば問題ないとは思うのですが、念のためこうしています。
商用利用
そういうわけで初心者ならかなりとっつきやすいLM Studioなのですが、もちろんライセンスが存在します。
ライセンスによるとソフト自体の無断での商用利用(おそらくサーバー利用など)はアウト。 出力に関して直接的な記載は見当たりませんが、禁止事項には「会社の財産またはその一部を商業または事業目的で使用すること」とあります。 この辺りも制限対象と思ったほうがよさそうです。
商用利用の場合は要連絡とのことです。
サイトトップのFrequently Asked Questions内にあるLM Studio @ Work request formから連絡できます。
Win環境で代替って何あるの
上記理由や今後の有償化への懸念から、別のものを使うべきという声も上がっています。 Janという商用利用可能(AGPL 3.0ライセンス)なGUI付きローカルLLMツールが、LM Studioの代替として挙がることが多いようです。
私も試してみましたが、Radeon環境で使うにはまだ時期が早いでしょう。 Linux環境のROCmすら非対応です。 拡張設定からVulkanを有効化すればWindowsでも一応扱えましたが、モデルのGPUメモリ使用量が12GBを超える場合読み込みに失敗(LM Studioで緑マークとなるデータは多分大丈夫)、 その他諸々の細かいところで弱い部分もあります。 ただ、去年出たばかり(多分)のフリーソフトに色々要求するのも酷な話ですし、Radeon正式対応に向けた動きも一応あるみたいなので、 今後に期待ということで…
Windowsネイティブでは他にKoboldcppとOllamaという手もあるのですが、
Koboldは本家とROCmフォーク版の両方ともMD表示で出力が途中で止まり、日本語表示がうまくいきません(CLI上の表示は正常な場合あり)。
MD表示はAnythingLLM等を通すと対策できますが、日本語が解決できず。
調べると日本語向けに外部翻訳ツールがわざわざ存在したので、そういうものらしいです。
LLM定番と言われるOllamaは今年Windows HIP SDkに正式対応していますが、何この変換処理n○d.aiかよ…多分もう触ることないです。
変換してる訳ではないらしい。あとこれ自体のhaggingFace DL機能だとModelfile不要で、GGUF手動追加時と扱いが微妙に異なるらしい。
入れ直してこれ経由してDLする気力がもう無いので未確認。
その他Vulkan動作のマイナー系も五十歩百歩といったところ。
番外としてtext-generation-webuiにおいて、llama.cppのWindows HIP SDK用ビルドを作成すると動作したという情報もありました。
ビルド後に何をどうするのかよく分からず、テスト出来ていません。
結論 : LM Studioつよい
Janは今後次第、割り切って英語で使うならKoboldcppもアリ。
GeforceならWinだろうと多分どうにでもなります。
あとがき
以上、LLM入門した話でした。
今回試し終わって最初に思ったことは、
16GBじゃ足りねえんやなって…
AI絵生成は処理速度さえ高ければ低メモリでも手はあるようですが、LLMはダメです。 後から誤魔化しがきかないのでシンプルにメモリ容量が質に直結します。
そもそもWindows & RadeonだとAI絵に比べて環境がさらにキツイ。 AI絵だと大活躍のZLUDAも、こちらでは活用例が無い模様…
仕事で使う訳じゃないならLM Studioあるだけマシ感。 てか業務なら多分それ用にシステム組むよね。
…
業務でも課金のほうが多いのでは…?